
2023年4月中頃に「ControlNet(コントロールネット)」のバージョン1.1がリリースされています。既に色々なところで話題になっていることから、公開直後から利用されている方も多いと思います。それでも、これから新たに利用することを考えている方や、前バージョンからの更新を考えている方も数多くいらっしゃるはずです。
この新しいバージョンでは、前バージョンのモデルに改良が加えられたり、さらに新しいモデルが追加されたりしています。「ControlNet」はプリプロセッサとモデルを組み合わせて、その上で設定を正しく行う必要があるため、手順がどうしても煩雑に感じられるところがあります。しかも、日進月歩のAI関連技術は、新たに勉強しなければならないことが次から次へと増えていきます。
それでも「ControlNet」の習得を避けて通ることはできません。「ControlNet」は今ではAI画像生成になくてはならない拡張機能の代表格といえる存在です。そのため、「ControlNet 1.1」の新機能についても試行錯誤しながら理解を深めておく必要があるとえいます。
このページでは14種類のモデルのうち、新しく追加された6種類のモデルについて画像の生成を試してみました。モデルはいつものごとく「anything-v4.0」です。画像は基本的に512×768という解像度です。他はほぼデフォルトのままです。シード値もほぼ固定していません。プロンプトは再現しやすいように短く簡便なものにしています。
こちらの内容は5月20日時点のものになります。私もまだ使い方を試行錯誤しながら探究している状態ですので、理解不足によって間違っている可能性があります。これから導入される方の叩き台になれば幸いです。なお、内容や誤字脱字は随時加筆修正していく予定です。予めご了承ください。
「ControlNet v1.1.401」あたりの最新版では、設定画面が以下に掲載している画像とやや異なるところがありますが、プリプロセッサやモデルの設定方法は基本的に同じです(2023年9月6日追記)。

- 「ControlNet」はAI画像生成に不可欠な拡張機能
- 「ControlNet 1.1」の導入について
- 「ControlNet 1.1」の新モデルの基本的な使い方
「ControlNet」はAI画像生成に不可欠な拡張機能
「ControlNet」について理解する
「ControlNet 1.1」の詳細は以下のページにサンプルの画像とともに掲載されています。lllyasviel さんと Mikubill さんに感謝です。
これらのページを読んで大まかな機能を把握することが大切です。ですが、膨大な情報があるので読んですぐ理解することはできません。最初は気になるモデルをひとつ取り上げて、その使い方を探っていくのが良いと思います。とはいえ、「重要事項(important notice)」は少なくとも目を通しておく必要があります。
この他、「ControlNet」を「Stable Diffusion web UI」に導入する方法とその使い方は以下のページにもまとめてあります。こちらも併せてご覧ください。

拡張機能のインストールと「Stable Diffusion web UI」の更新
拡張機能を「Stable Diffusion web UI」にインストールする方法については以下のページをご覧ください。拡張機能は、拡張機能一覧からインストールすることもできますし、URLを指定してインストールすることもできます。
もしかすると「Stable Diffusion web UI」の更新が必要なことがあるかもしれません。その場合の更新方法は以下のページにまとめています。
「ControlNet 1.1」の導入について
「ControlNet」を更新して「ControlNet 1.1」にする
「ControlNet」をまだ導入していない方は拡張機能一覧から「ControlNet」をインストールしてください(上の項目参照)。既に導入している方は拡張機能の更新を行ってください。
更新方法は次のとおりです。

「拡張機能(Extensions)」タブを開いて「インストール済み(Installed)」内の「アップデートの確認(Check for updates)」をクリックします。

同タブ内の「適用してUIを再起動(Apply and restart UI)」をクリックするとインストールが完了します。

インストール完了後はボタンの下に上記のようなメッセージが表示されます。

更新後は「txt2img」タブ内と「img2img」タブ内の拡張機能から「ControlNet」のバージョンを確認します。
そこに「ControlNet v1.1.XXX」と表示されていれば「ControlNet 1.1」が正常にインストールされています。
「ControlNet 1.1」用のモデルを導入する
「ControlNet 1.1」を利用するためには拡張機能の更新に加えて、新しいモデルをダウンロードして指定のフォルダに移動させる必要があります。
「ControlNet 1.1」の利用に必要な各モデルは「Hugging Face(ハギング・フェイス)」の以下のページからダウンロードすることが可能です。
https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
そして「Files and versions(ファイルとバージョン)」ページに登録されているモデルのファイルをダウンロードします。
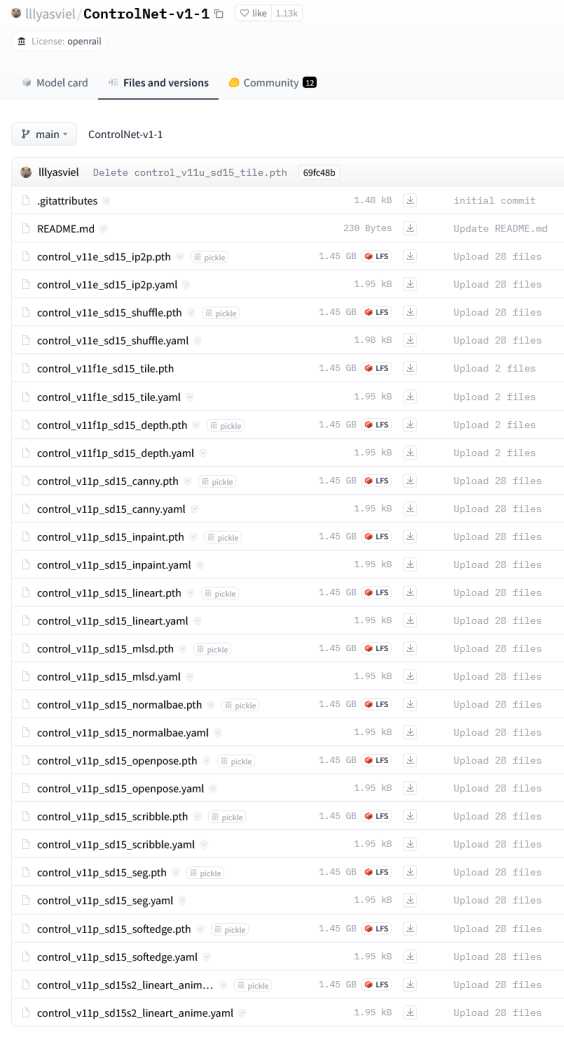
モデルは全部で14種類あります。これらは既存の8種類の改良版と新しい6種類のファイルです。
上記のページにある「control ~ 」というファイルをすべてダウンロードします。「↓」ボタンをクリックするとダウンロードが開始されます。
モデルのファイルが「.pth」という拡張子で、コンフィグファイルが「.yaml」という拡張子です。「.yaml」はなくてもよいらしいですが、ここでは「.yaml」も併せてすべてダウンロードしています。
モデルのファイルはひとつあたり1.45GBもあります。ストレージに余裕がない場合は利用するモデルだけをダウンロードしても構いません。あまり使わないものはダウンロードだけしてHDD等に保管しておくという手もあります。
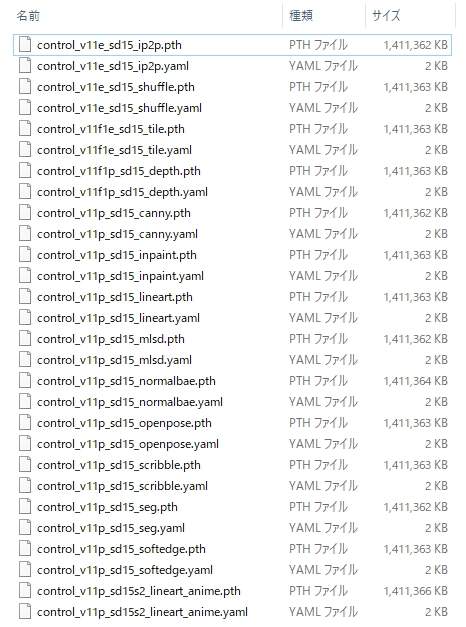
ダウンロードしたファイルは、「Stable Diffusion web UI」がインストールされたフォルダを開いていって「models」内にある「ControlNet」フォルダの中に移動します。今すぐ利用するモデルのファイルだけを入れても構いません。
これまで「ControlNet」を利用していた方は旧モデルが入っていますが、そのままにしておいても、別のところに一旦移しておいてもどちらでも問題ありません。でも、邪魔にならないところに移動させておいたほうが、モデル数が少なくなって見やすいかもしれません。


「ControlNet 1.1」の設定画面
![]()
「txt2img」タブ(または「img2img」タブ)の中にある「ControlNet v1.1.XXX」をクリックします。
モデルによっては「img2img」タブから使うことが好ましい場合もあるようです。
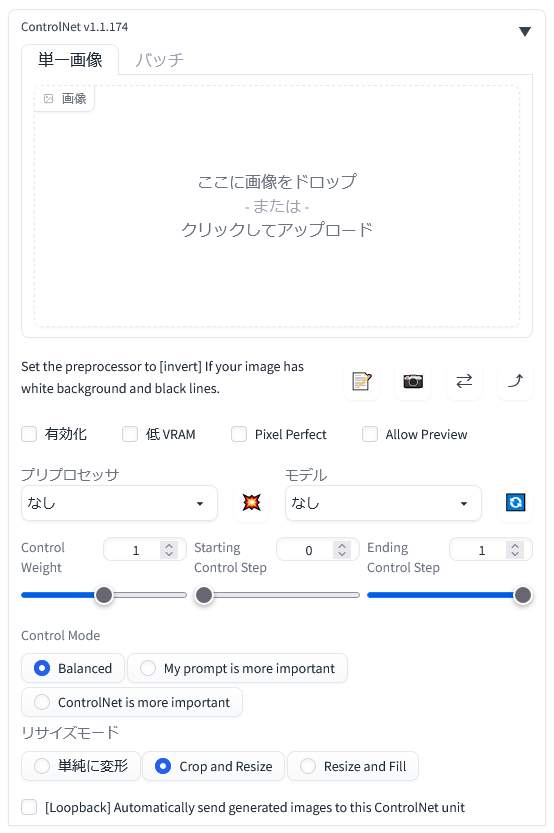
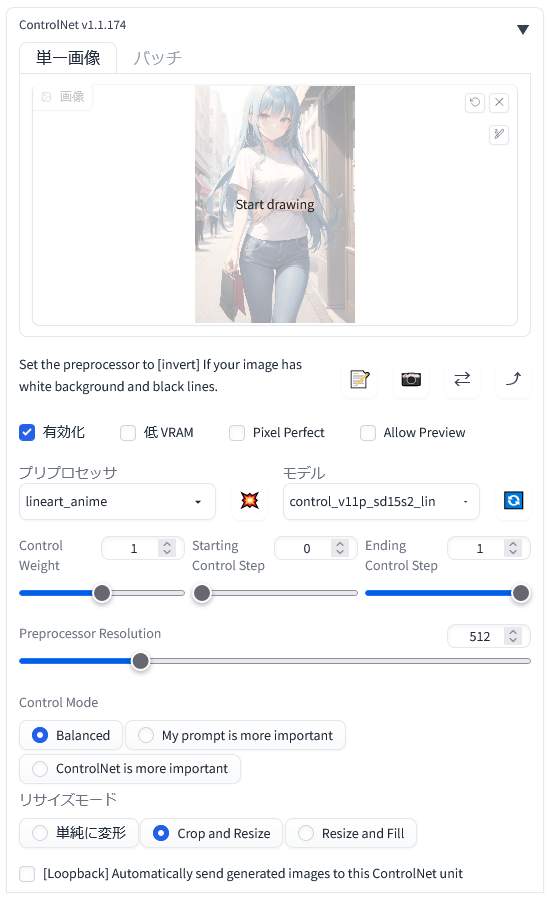
こちらが「ControlNet 1.1」の詳細設定画面です。元の画像は「ここに画像をドロップ – または – クリックしてアップロード」内に配置します。
参照するための画像を予め用意しておく必要があります。その画像を上のエリアに配置することになります。
![]()
「ControlNet 1.1」の利用時は「有効化(Enable)」にチェックを入れます。「プリプロセッサ(preprocess)」と「モデル(model)」は利用したいものを選択します。これらは対応したものを適切に組み合わせる必要があります。前処理が不要の場合は「プリプロセッサ(preprocess)」を「なし(non)」にします。
その他の設定はデフォルトのままでも画像の生成は可能です。
VRAM の少ないグラフィックボードを使用している場合は「低 VRAM」にチェックを入れます。「Pixel Perfect(ピクセル・パーフェクト)」はサイズの調整機能のようです。「Allow Preview(アラウ・プレビュー)」はプレビューを許可するという設定で、プリプロセッサを入れて右側の「※」っぽいボタンを押すと、上の画像欄が分割されて右半分にプリプロセッサ適用時のプレビューが出るはず。
「Control Mode」の「My prompt is more important(プロンプトを重視する)」と「ControlNet is more important(CNの設定を重視する)」、それらの折衷である「Balanced(バランスのとれた)」があるということだと思います。これもとりあえずデフォルトの「Balanced」でOKです。
他の細かい設定はまだ少ししか試せていませんので何も言及できません。ですが、これらの設定は数値をほんのちょっと変えただけでは変化らしい変化は見られません。
対応した「プリプロセッサ」と「モデル」を組み合わせる
「プリプロセッサ(preprocess)」は画像の前処理を行うためのものです。たとえば、画像生成の前段階として、線画を抽出したり奥行きを抽出したりといった用途で用いられています。
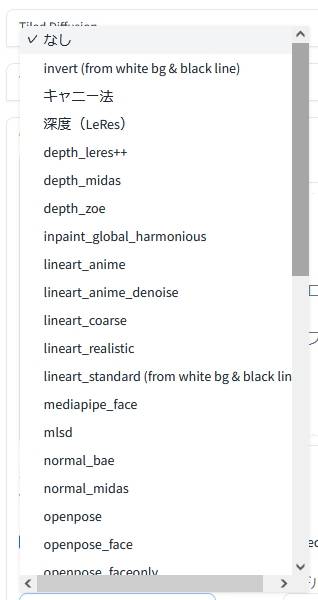 |
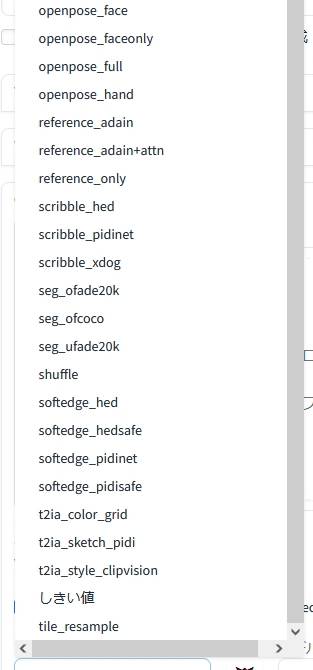 |
| プリプロセッサ(上半分) | プリプロセッサ(下半分) |
利用する「モデル(model)」に対応していない「プリプロセッサ(preprocess)」を選択していると、ほとんどの場合にエラーが生じて画像は生成されません。
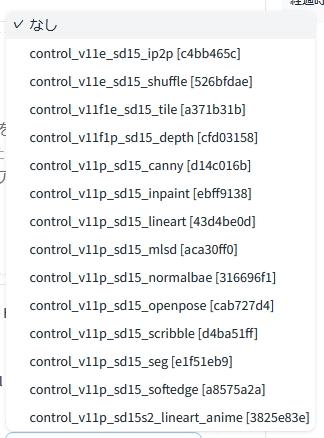
「モデル(model)」は14種類から利用したいものを選びます。これは先ほどの「プリプロセッサ(preprocess)」と対応しているものでなければなりません。
ただし、例外もあります。「reference_only」のように対応する「モデル(model)」がないものもあります。「reference only」「reference adain」「reference adain attn」の詳細については以下のページをご覧ください。

モデル一覧と「ControlNet 1.1」の新モデル
「ControlNet 1.1」では、新しいモデルが6つ追加されるとともに、既存のモデルも改善や機能追加が行われています。
| ControlNet 1.1 | 旧 ControlNet | モデルファイル |
| Instruct Pix2Pix | – | control_v11e_sd15_ip2p |
| Shuffle | – | control_v11e_sd15_shuffle |
| Tile | – | control_v11f1e_sd15_tile |
| Inpaint | – | control_v11p_sd15_inpaint |
| Lineart | – | control_v11p_sd15_lineart |
| Lineart anime | – | control_v11p_sd15s2_lineart_anime |
| Canny | Canny | control_v11p_sd15_canny |
| Depth | Depth | control_v11f1p_sd15_depth |
| Softedge | HED | control_v11p_sd15_softedge |
| MLSD | MLSD | control_v11p_sd15_mlsd |
| Normal | Normal | control_v11p_sd15_normalbae |
| Openpose | Openpose | control_v11p_sd15_openpose |
| Scribble | Scribble | control_v11p_sd15_scribble |
| Segmentaion | Segmentaion | control_v11p_sd15_seg |
「v11」の右側の「e」は「experimental(実験的な)」を意味し、このモデルが現段階において実験的に導入されたモデルであることを示しています。「p」は「produciton-ready(本番用)」を意味し、既にリリース可能な状態を示しています。また「u」は「unfinished(未完成の)」を意味し、今モデルには該当するものこそありませんが未完成な状態を示しています。
新たに定められた命名規則は公式サイトに詳しい説明があります。気になる方はそちらをご一読ください。新しいモデルが開発されたり、異なるサービスで用いられたりする際に混乱が生じないようにするための措置と思われます。
旧バージョンのモデルが入っている場合には、これとは別に表示されたはずです。

「ControlNet 1.1」の新モデルの基本的な使い方
「Instruct Pix2Pix(ip2p)」は画像の一部に対して変更を指示できる
「Instruct Pix2Pix(ip2p)(インストラクト・ピクセル・トゥ・ピクセル)」は現在のところ実験的に搭載された機能のようです。このモデルを利用することで、元の画像の一部を別の要素と置き換えることができます。
参照元の画像とする画像を1枚用意しました。元の画像は以前に以下のページで生成したものです。

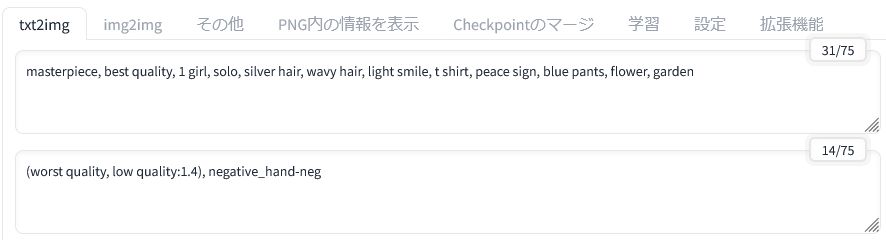
画像を生成したときのプロンプトは上記の通りです。なお、次の項目からは参照するための元となる画像を新たに生成しています。そちらではネガティブプロンプトに Embeddings を使わないようにしたので再現も容易になると思います。
画像が用意できたら「txt2img」ではなく「img2img」タブ内で「ControlNet 1.1」の設定画面を開きます。
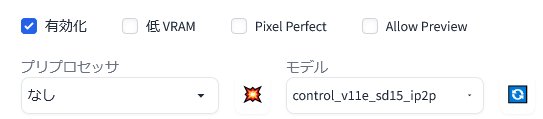
「ControlNet 1.1」を「有効化(Enable)」します。そして、「モデル(model)」に「control_v11e_sd15_ip2p」を選択します。このモデルには「プリプロセッサ(preprocess)」がありませんので「なし」のままです。
参照元の画像は「ここに画像をドロップ – または – クリックしてアップロード」内に配置します。
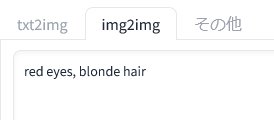
そして、「img2img」のプロンプト欄には画像をどう変更したいのかについてのプロンプトを入力します。この場合は、「目の色を赤くして、髪の毛はブロンドにしてください」と指示しています。
命令文は本来「make ~」「replace ~」のような英語で入力します。そして「A を B にする」「C を D に置き換える」と指示するわけです。とはいえ、目の色や髪色程度であれば単語だけでも難なく変更できるようです。
 |
 |
| 元の画像 | 新しく生成した画像 |
新しく生成された画像は元の画像とほとんど同じですが、指示通りに「赤い目・ややブロンド」になっていることが分かります。
このように画像の部分的な変更を実行することができます。
別の機会に他の要素を変更してみようと思います。もしかすると参照する画像の内容によっても特定の要素が置き換えやすいかどうかといったことが変わってくるかもしれません。もっと適切な例もまた後日に用意しようと思っています。

「Shuffle」は参照元の画像を組み替えて再構成する
「Shuffle(シャッフル)」も現在のところ実験的に搭載された機能のようです。この「Shuffle」を利用することで、元の画像を再構成することができます。Random Flow を用いて画像をシャッフルして画像を組み替えるとのことです。
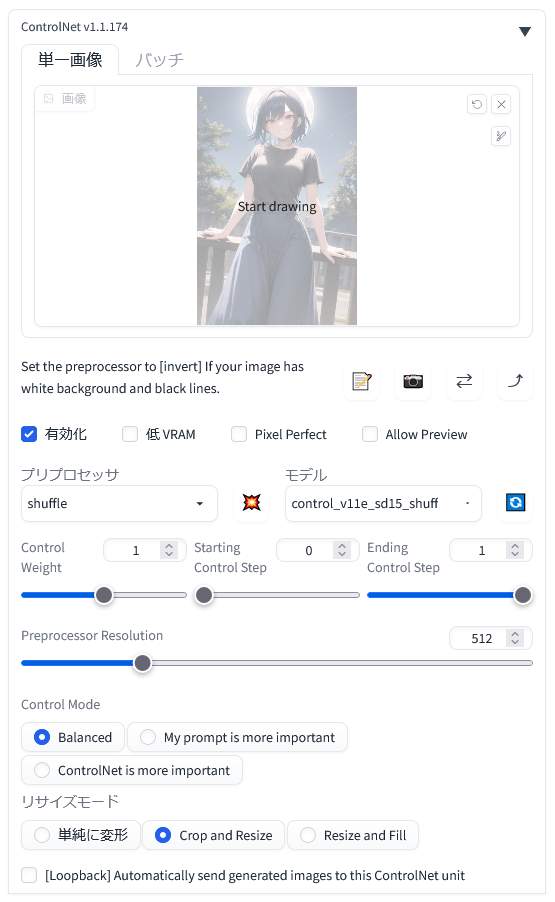
まず「ControlNet 1.1」を「有効化(Enable)」します。
それから「プリプロセッサ(preprocess)」に「shuffle」を選択して、「モデル(model)」に「control_v11e_sd15_shuffle」を選択します。
元の画像は「ここに画像をドロップ – または – クリックしてアップロード」内に配置します。
 |
 |
 |
| 元の画像 | シャッフル | 新しい画像 |
参照元の画像をシャッフルして再構成することで新しい画像の生成を行うようです。真ん中の画像がシャッフルされた状態で、こちらも出力結果の領域に表示されます。
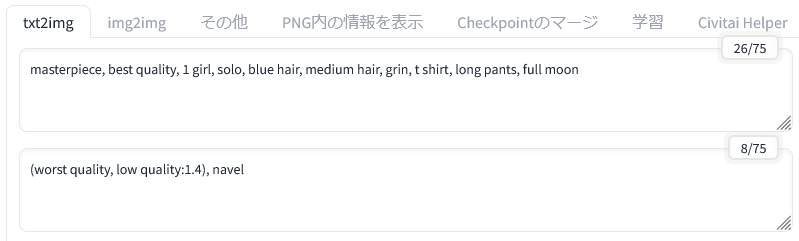
新しく生成された画像のプロンプトは、元の画像のものから一部変更したものになります。元の画像では「long skirt」となっていた部分を「long pants」に変更しています。そういう変更も新しい画像に反映されています。
画像を何度も繰り返し生成してみましたが、こちらの環境では全体的な色合いが VAE を変えたかのようにやや変化しています。

「Tile」は画像を精細化して高解像度化の際にも役立つ
「Tile(タイル)」は以前まで「control_v11u_sd15_tile」という未完成のモデルだったようですが、今では「control_v11f1e_sd15_tile」として実験的モデルという位置づけになっているようです。
このモデルは画像のディテールを無視して、新しいディテールを生成することができます。それによって、拡大時に生じたぼやけを除去するといったことができるとのことです。
また、画像を高解像度化する際にキャンバスをタイル状に分割して描画を行う方法が主流となっていますが、その際にプロンプトが各タイルに影響を及ぼすことがあります。そのような問題を解消することも念頭において開発されているようです。
各タイルの解釈とプロンプトが一致していないときに全体的なプロンプトを無視して、ローカルコンテキストで拡散を方向付けるとあります。各タイルの意味を重視して全体的なプロンプトの影響力を低減した上で画像を生成するということでしょうか。
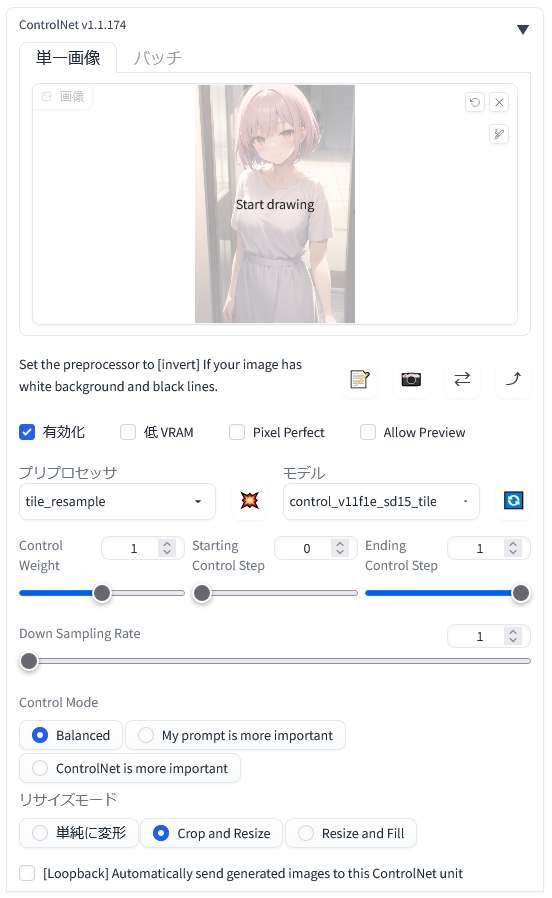
「ControlNet 1.1」を「有効化(Enable)」します。
「プリプロセッサ(preprocess)」に「tile_resample」を選択して、「モデル(model)」に「control_v11f1e_sd15_tile」を選択します。
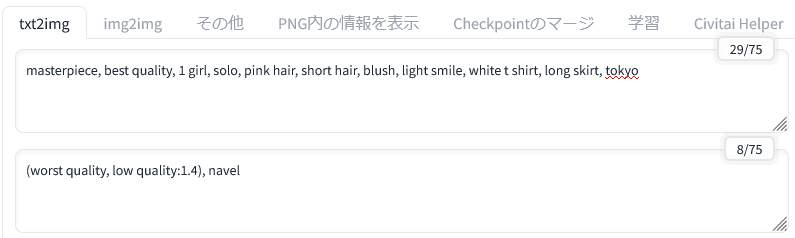
こちらが参照元の画像のプロンプトです。ネガティブプロンプトからは「おへそ」の出現を食い止めようとするブログ主の工夫が読み取れますね……。
元の画像は「ここに画像をドロップ – または – クリックしてアップロード」内に配置します。
 |
 |
| 元の画像 | 新しい画像 |
新しい画像は元の画像の状態をある程度保ったまま細部まで細かく描画されています。右側の画像は元画像と同じサイズで生成しています。ディテールの再描写ないしは修正ができるという点は利便性が高そうです。
これは以前ご紹介した「flat」LoRAと似ているような気がします。「flat」LoRAがマイナス適用でネガティブ方向(やや暗い感じ)に精細化されているとすると、こちらはポジティブ方向に精細化されているといった印象を受けます。

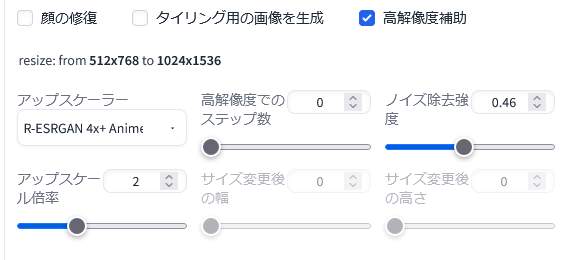
「Tile」に「高解像度補助(Hires.fix)」を併用して2倍に拡大してみました。ブログ掲載画像は当然ながら縮小しています。
|
 |
| 元の画像 | 高解像度補助による画像 |
参照元の画像の状態を保持したまま細部をやや精細化して拡大することができるようです。
画像を普通に高解像度化すると元の画像から大きく変更された画像になることも少なくありませんが、そうした問題は「Tile」を併用することによって回避できるのではないでしょうか。こちらのモデルはアップスケールを行う際に活用できそうです。

「Inpaint」は従来どおり画像の部分的な修正と変更ができる
「Inpaint(インペイント)」は画像の中の選択した範囲を書き換えるための機能です。
この機能は「Stable Diffusion web UI」にも普通に含まれていますが、今回それと同様の機能が「ControlNet 1.1」にも実装されたかたちになります。
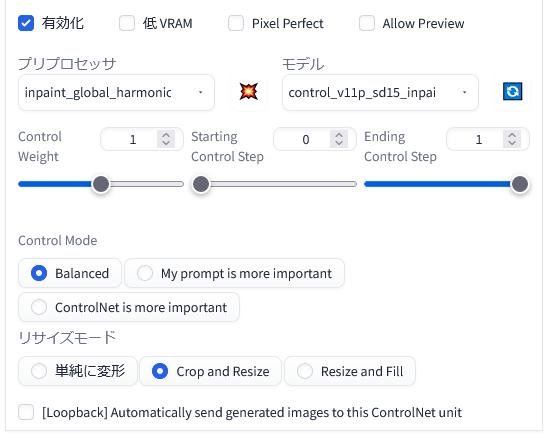
「ControlNet 1.1」を「有効化(Enable)」します。
「プリプロセッサ(preprocess)」に「inpaint_global_harmonic」を選択して、「モデル(model)」に「control_v11p_sd15_inpaint」を選択します。
こちらが元の画像のプロンプトです。
元の画像は「ここに画像をドロップ – または – クリックしてアップロード」内に配置します。

この機能は標準の「inpaint」と同じように使えます。
画像の中の変更したい部分をペンで塗りつぶします。塗りつぶす範囲はできる限り正確なほうが望ましいです。

表情に関するプロンプトを「light smile」から「smirk」に変更してみます。その他のプロンプトは変更していません。
 |
 |
 |
| 元の画像(light smile) | 表情の変更(smirk) | 表情の変更(anger) |
指定した部分だけが変更されています。この場合は表情が変わっています。ただし、顔の大きさ(形や輪郭)も少し変わっています。範囲の指定は丁寧に行うほうが良さそうです。
ここで生成した2枚の画像(中央と右側)は細部を見るとノイズのようなものが混ざって画像がやや粗くなっています。たとえば、腰をかけている台のところに白い点が追加されてしまっています。このあたりは設定等を見直してみる必要がありそうです。
「Lineart」は色々な線画を抽出して新しい画像を生成できる
「Lineart(ラインアート)」は参照元の画像から手描きのような線画を抽出して、その輪郭線に基づいて新しい画像を生成します。このモデルでは、「プリプロセッサ(preprocess)」を切り替えることによって、線画の抽出スタイルを細かく変化させることができます。
そのことは抽出された線画を比較すると一目瞭然です。そちらは後半にまとめて掲載しています。
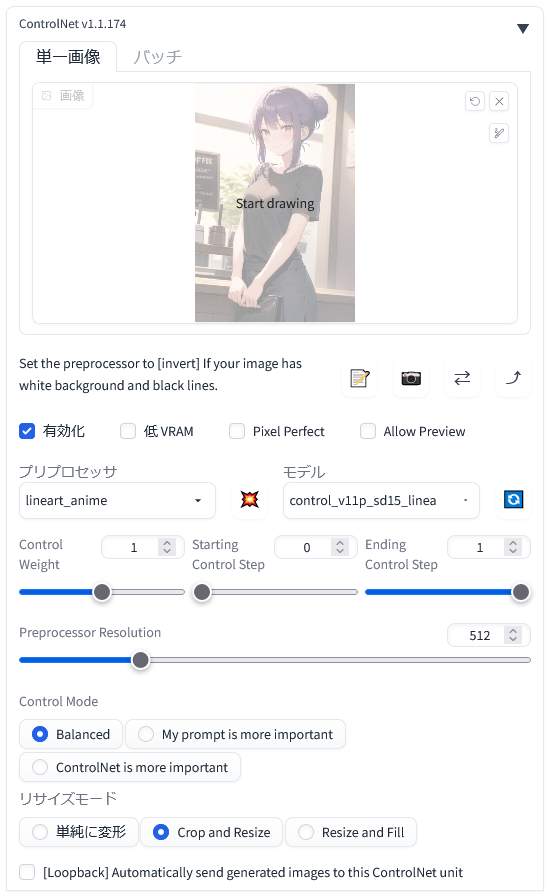
「ControlNet 1.1」を「有効化(Enable)」します。
「プリプロセッサ(preprocess)」に対応した「lineart_〇〇」を選択して、「モデル(model)」に「control_v11p_sd15_lineart」を選択します。
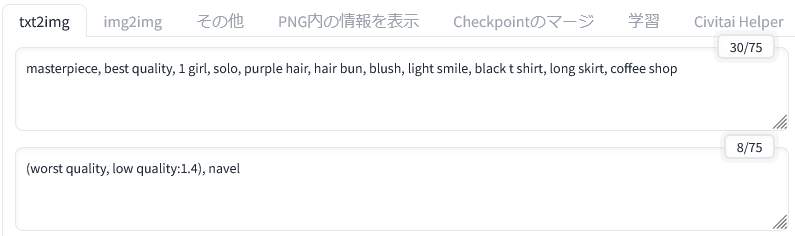
こちらが元の画像のプロンプトです。このプロンプトを「プリプロセッサ(preprocess)」を変更しながら使用してみました。
新しく生成された画像は「プリプロセッサ(preprocess)」ごとの差異が際立っています。
プリプロセッサ「lineart_coarse」
 |
 |
 |
| 元の画像 | 抽出された線画 | 生成された画像 |
ボディラインが線画にしっかりと表現されています。服の皺のような細かい線はあまりみられません。
プリプロセッサ「lineart_realistic」
|
 |
 |
| 元の画像 | 抽出された線画 | 生成された画像 |
こちらは繊細な輪郭線が抽出されています。線は上の先ほどのものよりも明らかに細いです。背景や服の皺なども線画に現れています。
プリプロセッサ「lineart_standard」
|
 |
 |
| 元の画像 | 抽出された線画 | 生成された画像 |
こちらはもっとも太い線画が抽出されているところに特徴がみられます。背景は割と正確に再現されています。
プリプロセッサ「lineart_anime」
|
 |
 |
| 元の画像 | 抽出された線画 | 生成された画像 |
こちらはもっとも細い線が抽出されています。
プリプロセッサ「lineart_anime_denoise」
|
 |
 |
| 元の画像 | 抽出された線画 | 生成された画像 |
こちらは上の線画をより太い線でなぞったような線画になっています。「lineart_anime」のノイズを除去するバージョンということでしょうか。
各プリプロセッサの生成画像と線画の比較
|
|
|
|
|
| lineart_coarse | lineart_realistic | lineart_standard | lineart_anime | ~ anime_denoise |
|
|
|
|
|
新たに生成された画像とその元となった線画を並べて比較してみるとその違いが見てとれます。「プリプロセッサ(preprocess)」は必要に応じて好みのものを選ぶと良さそうです。
次に、画像の一部のカラーを変更してみることにしました。
プロンプトの変更によるカラーの一部変更

プロンプトを一部変更して、髪の毛の色と服の色を変更してみます。
|
 |
 |
 |
| 元の画像 | 新しい画像1 | 新しい画像2 | 新しい画像3 |
髪の毛の色は指定した通りにピンク色に変わりましたが、服の色は「white」を強調したもののピンク色指定の影響が強く出てしまいました。画像を何枚生成しても同じような具合です。
細かい色の指定は別の方法で変更したほうがよいかもしれません。

「Lineart anime」はアニメのような線画を抽出して画像を生成できる
このモデルは実際のアニメのような線画を抽出して、新しい画像を生成することができます。
(デモの再現には)「anything-v3-full.safetensors」という(画風の)モデルを使用するように付記されています。他のモデルを使用しているとデモと同じような効果が得られない可能性があります。
なお、ここでは「anything-v4.0」というモデルを一貫して使用しています。同じようなものだから別にどっちでもいいよね、の精神。
また、LoRA を適用しない限り、ロングプロンプトのほうが良い結果になるそうです。
「ControlNet 1.1」を「有効化(Enable)」します。
「プリプロセッサ(preprocess)」に対応した「lineart_〇〇」を選択して、「モデル(model)」に「control_v11p_sd15s2_lineart_anime」を選択します。
このモデルでは「anime」と書かれている「lineart_anime」と「lineart_anime_denoise」という二つの「プリプロセッサ(preprocess)」を組み合わせてみました。他の「lineart_〇〇」も使えるかもしれませんがまだ試していません。
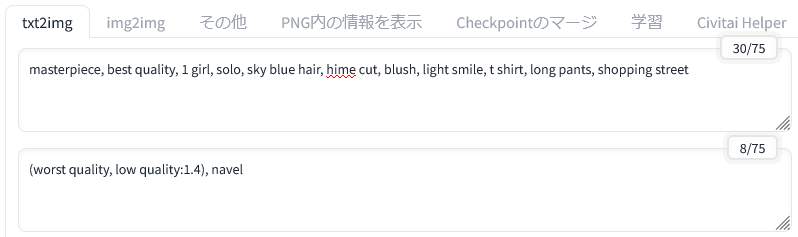
こちらが参照元の画像のプロンプトです。
プリプロセッサ「lineart_anime」
 |
 |
 |
| 元の画像 | 線画 | 新しい画像 |
繊細な線が抽出されています。
生成された画像の塗りも先ほどの「Lineart」モデルと比べて、よりアニメっぽい感じになっています。
プリプロセッサ「lineart_anime_denoise」
|
 |
 |
| 元の画像 | 線画 | 新しい画像 |
こちらは「lineart_anime」よりも輪郭線がくっきりと表現されています。ノイズ除去を行って線をはっきりと表現しているのでしょうか。
どちらがお好みでしょうか?
「ControlNet 1.1」の新モデルはどれも有用性が高くて魅力的!
今見てきたように「ControlNet 1.1」は新しく追加されたモデルだけでも色々な表現ができるようです。それぞれのモデルをどういう場面で適用するとより効果的かということを考えてみてください。
また「ControlNet 1.1」は、別の拡張機能と上手く組み合わせることによって可能性が大きく広がっていくものと思われます。
まだお試しになっていない方は、これを機会に導入を検討してみてください。どれかひとつでも利用してみると新しい発見があるかもしれません。
このページの内容は随時加筆修正を行っていく予定です。他のページも併せてご覧いただけますと幸いです。

