
「Stable Diffusion(ステーブル・ディフュージョン)」では、プロンプト(呪文)を入力することによってさまざま登場人物を描いてもらうことができます。しかし、プロンプトを入力するだけでは自分の想像と違ったポーズをとった人物の画像が生成されてしまうことが多々あります。

そこで「ControlNet(コントロールネット)」という拡張機能をインストールすることによって、参考写真と同様のポーズをとらせることが可能になります。また、「3Dモデル」「デッサン用の人形」「棒人間」などと同様のポーズをとらせることもできるようになります。
このページでは「Stable Diffusion web UI」に「ControlNet」をインストールする手順とその使い方について画像付きで紹介しています。項目名は日本語と英語を併記しています。モデルは「anything-v4.0」を利用しています。
2023年4月中旬に「ControlNet 1.1」がリリースされています。そちらについては導入方法と新モデルの使い方を以下のページにまとめています。このページと併せてご覧ください。

(2023年5月25日追記)
新しく追加されたプリプロセッサである「reference」シリーズについてまとめています。これを使うと同じキャラの画像を連続で生成できるようになります!

ポーズを読み込ませる方法はいくつもありますが、ここではもっともシンプルな方法を二つ取り上げています。とりあえず、画像を参照元としてポーズを固定することができれば画像生成の可能性が広がります。
私もまだ使い方を模索している状態ですので、初心者による初心者のために解説としてご理解いただければと思います。皆で使い方をマスターしていきましょう。内容をより分かりやすくするために修正と補足を入れました(2023年4月13日追記)。
「ControlNet v1.1.401」あたりの最新版では、設定画面が以下に掲載している画像とやや異なるところがありますが、設定方法自体は基本的に同じです(2023年9月6日追記)。

「ControlNet」の導入方法
「Stable Diffusion web UI」に拡張機能「ControlNet」を導入する
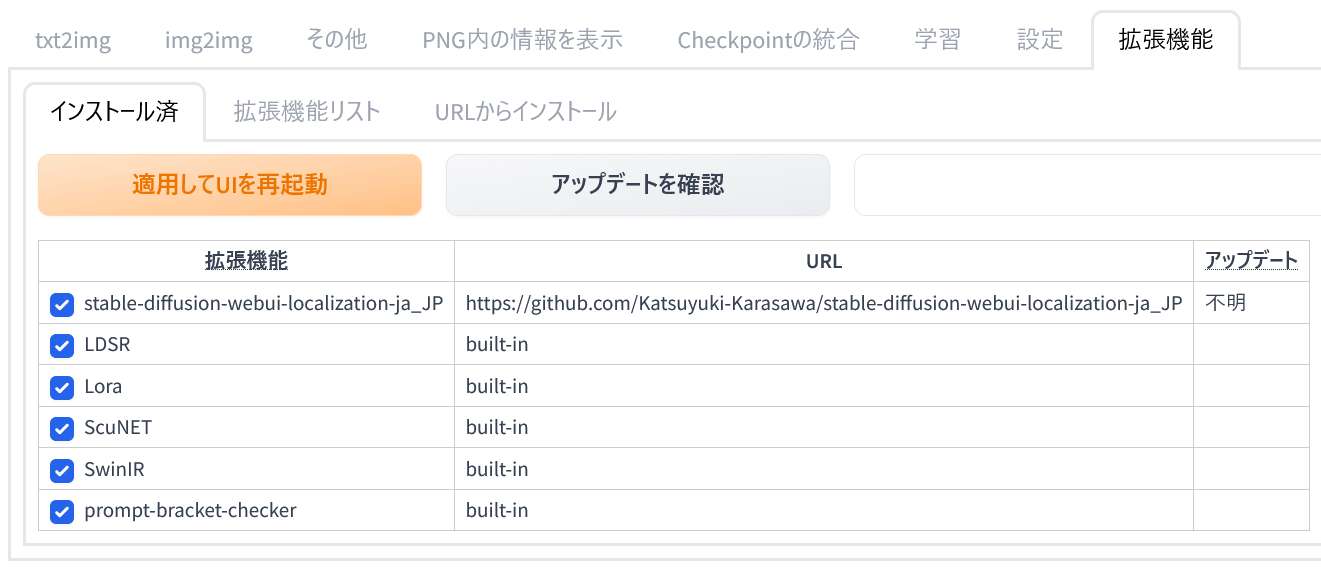
「Stable Diffusion web UI」を起動したら「拡張機能(Extensions)」のタブを開きます。
「インストール済(Installed)」内の拡張機能(Extension)を見ると「ControlNet」はまだ入っていないことが分かります。ここに「ControlNet」を追加します。
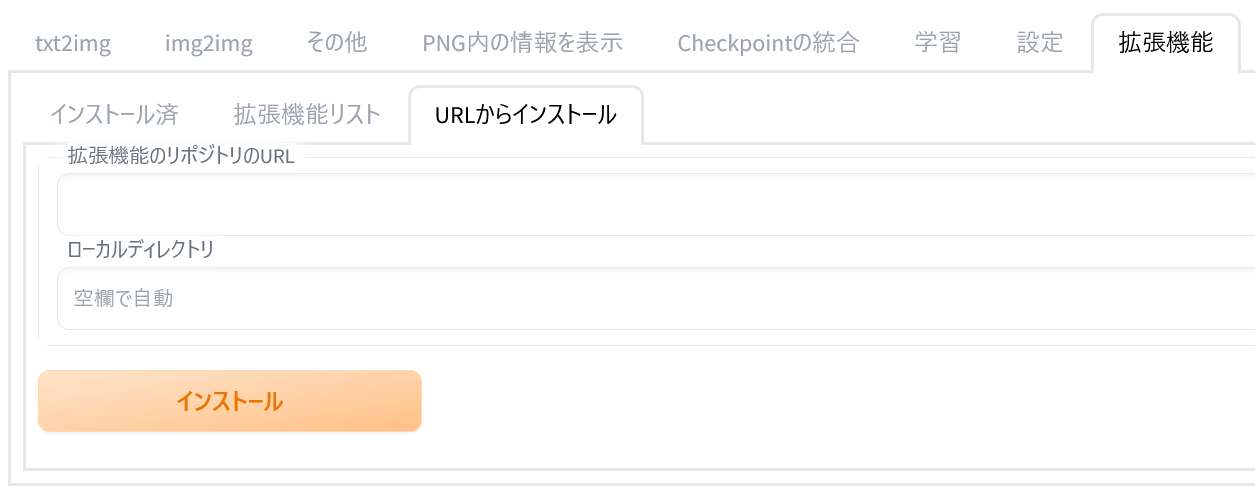
タブを「URLからインストール(Install from URL)」に切り替えてください。そして「拡張機能のリポジトリのURL(URL for extension’s repository)」欄に以下のURLを貼り付けてください。
URLを貼り付けたら「インストール(Install)」ボタンをクリックしてください。そうすることで「GitHub」に置かれているファイルを自動的にインストールしてもらえます。
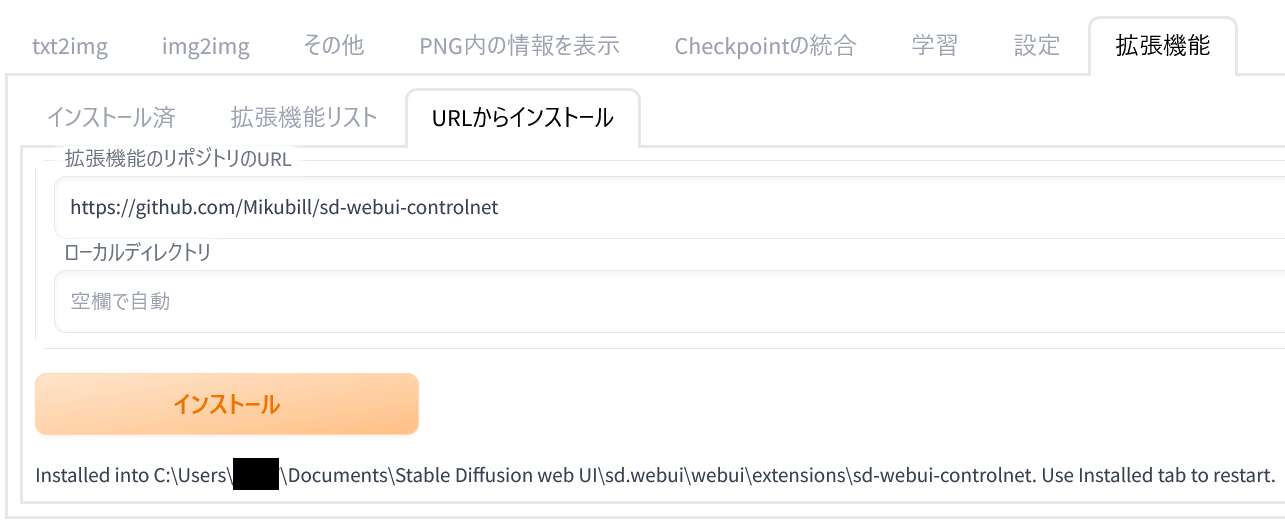
インストールはすぐに完了します。ファイルが「sd-webui-controlnet」フォルダにインストールされたことが表示されます。「■」にはあなたのユーザーネームが表示されています(←SDをインストールしている場所によって表記が異なります[補足])。
それとともに「インストール済(Installed)」タブに戻って再起動を促すメッセージが表示されます。
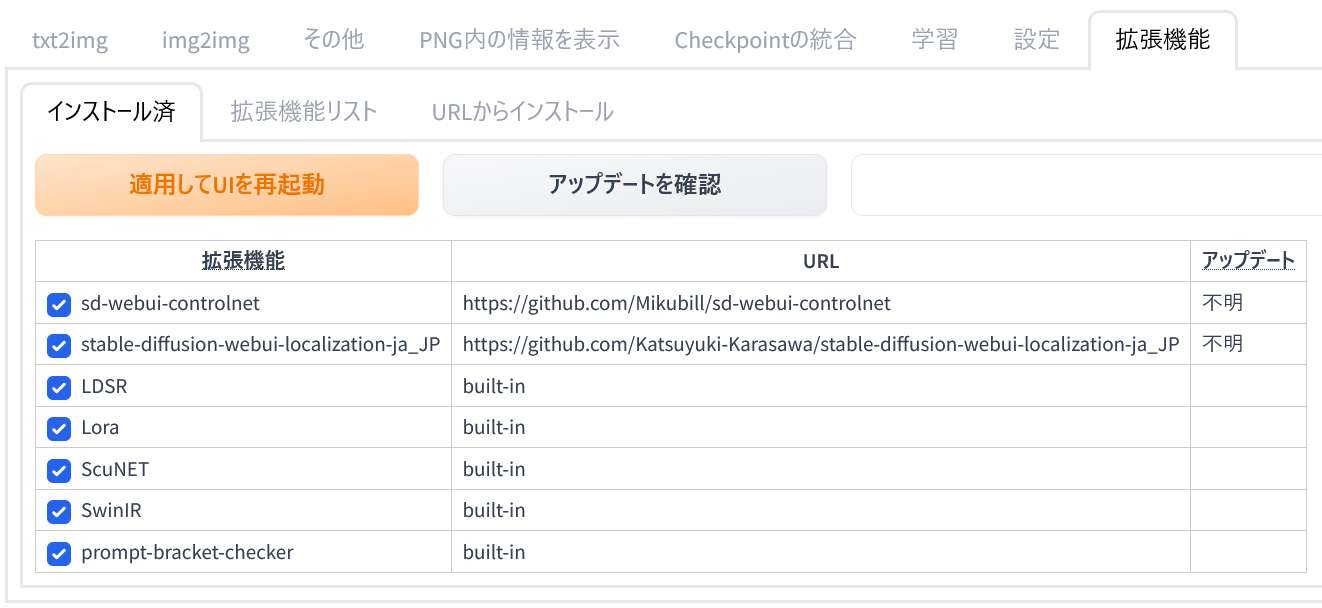
「インストール済(Installed)」タブに切り替えて、「適用してUIを再起動(Apply and restart UI)」をクリックしてください。
拡張機能の一覧に「ControlNet」が追加されています。
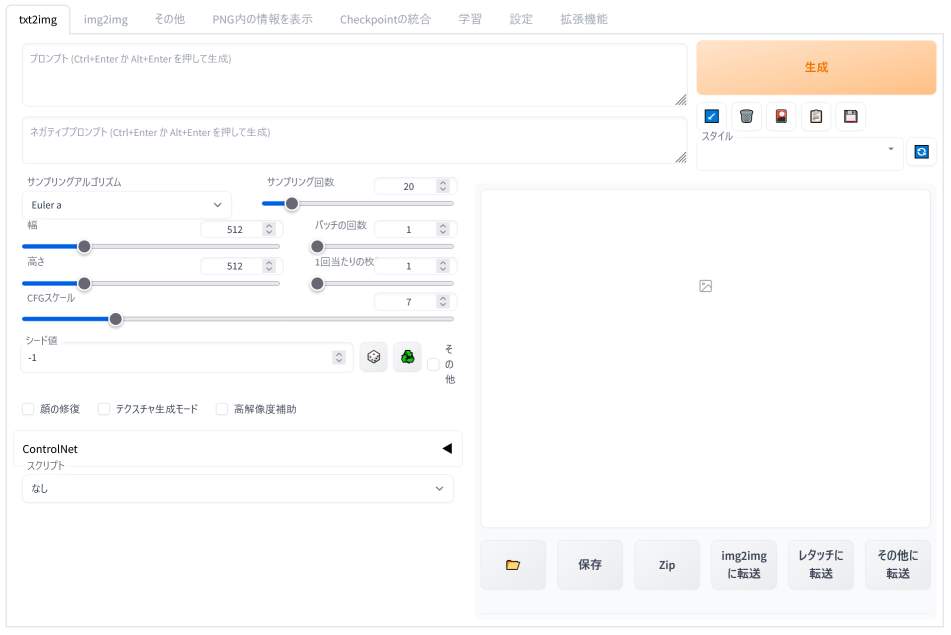
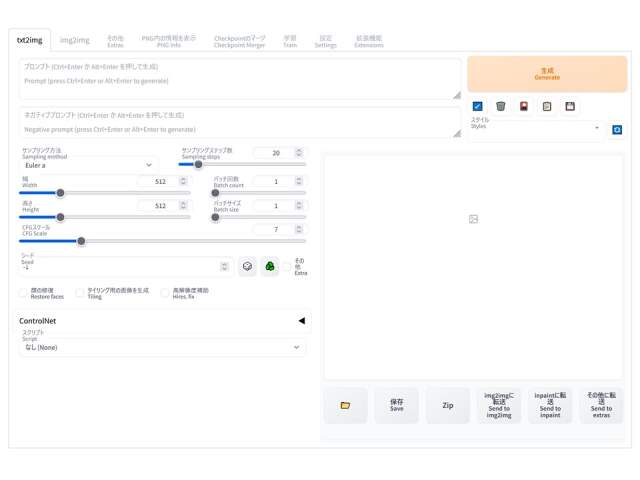
「txt2img」タブに切り替えてみると、ページの左下に「ControlNet」という項目が新たに追加されていることが分かります。
次の作業は「ControlNet」を利用するために必要なファイルを用意することです。「Webブラウザ」と「コマンドプロンプト」を閉じて「Stable Diffusion web UI」を一旦終了してください。
「ControlNet」の「モデル」をDLして所定のフォルダに配置する
「ControlNet」を利用するためには専用の「モデル」が必要です。「モデル」のファイルをダウンロードして所定のフォルダに配置します。
「Hugging Face(ハギング・フェイス)」にある以下のページにアクセスしてください。
すると次のページが開きます。
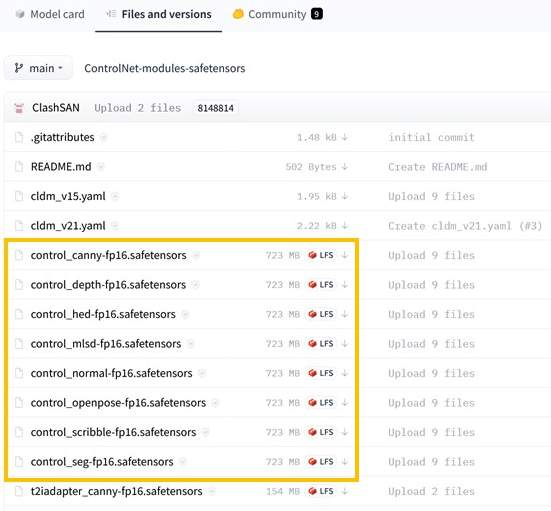
オレンジ色で囲っている8個のファイルが「ControlNet」用の「モデル」になります。こちらを使わせてもらいましょう。これらの「モデル」はそれぞれ異なる役割を持っています(=できることが違います)。
ストレージに余裕のある方はすべてのファイルをダウンロードしておいてください。
今回の説明では主要な二つを取り上げるため、一番上「control_canny-fp16.safetensors」と下から三つ目の「control_openpose-fp16.safetensors」の二つをダウンロードしてください。
ダウンロードしたファイルは「Stable Diffusion web UI」がインストールされているフォルダを開いて「sd.webui」→「webui」→「models」の下にある「ControlNet」フォルダ内に移動させてください。
このページでは、とりあえず「control_canny-fp 16.safetensors」と「control_openpose-fp 16.safetensors」の二つを「ControlNet」フォルダ内にコピーしています。
これで「ControlNet」を利用するための準備が整いました。「Stable Diffusion web UI」を起動してください。
最初の「txt2img」タブの画面下にある「ControlNet」という項目をクリックすると上のような詳細設定の画面が開きます。
ここで先ほどの「モデル」を指定するとともに、ポーズの基となる「画像」を配置することになります。

「ControlNet」の使い方
写真や画像を使ってポーズを指定する(「canny」の利用)
「ControlNet」の利用に必要な設定は以下の3点です。あとは詳細設定になります。
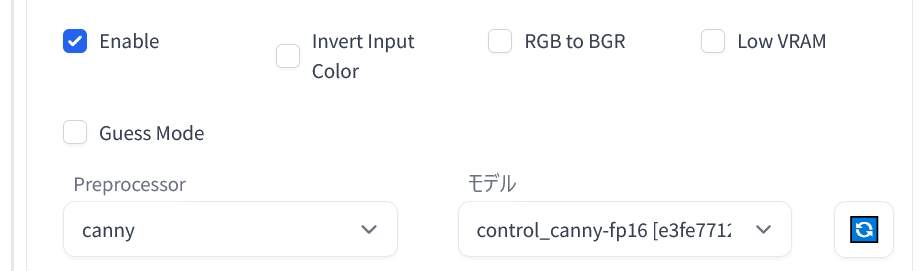
まず「ControlNet」を利用するときだけ「Enable(有効化)」にチェックを入れます。
「Invert Input(入力の色を反転)」「RGB to BGR(色の変換)」「Low VRAM(低ビデオラム)」「Guess Mode(推測モード)」はデフォルトのままで構いませんが、VRAMの少ないグラボをお使いの方は「Low VRAM」にチェックを入れて試してみてください。
「ControlNet」の利用を止めるときはチェックを外します。この切り替えは忘れないでください。
次に「Preprocessor(プリプロセッサ)」に「canny(キャニー法)」を指定します。そして「モデル」には「control_canny-fp16」を指定してください。
「canny(キャニー法)」は参照元画像の輪郭線を抽出して、それに基づいて生成する画像のポーズを設定しているようです。
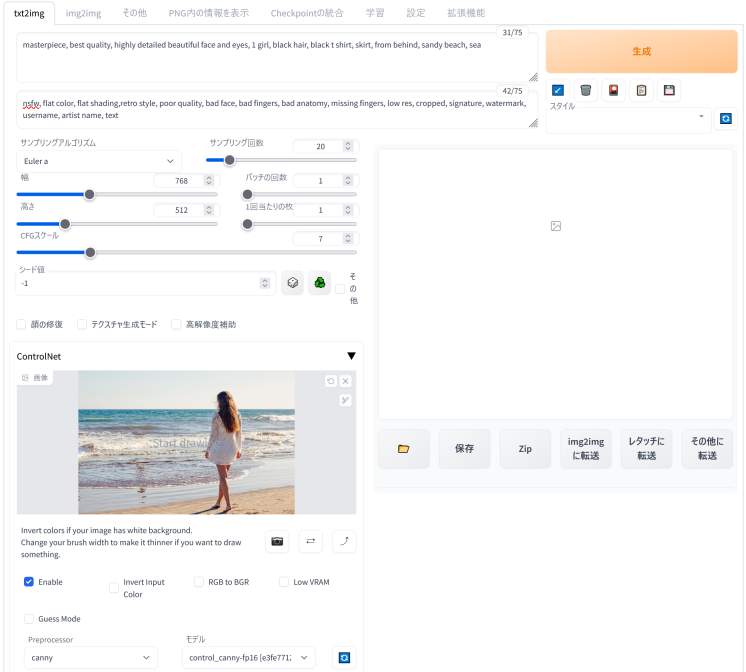
ここでは、「フリー素材」のサイトからダウンロードした1枚の写真を使用しています。何か適当な画像を用意してみてください。最初は人物がはっきりと写っているような写真がよいと思います。以下はフリー素材サイトの一例です。
適切な画像を「ここに画像をドロップ-または-クリックしてアップロード」欄に配置してください。
そして、いつもと同じようにプロンプトとネガティブプロンプトを入力して、各種設定を行ってから「生成」ボタンをクリックします。そうすると指定した画像のポーズと同じポーズをとった人物の画像が生成されます。
(追記&訂正)プロンプトは品質に関わるものを適当に入れておくだけでも問題なさそうです。ControlNetがオンになっている状態では、あえて異なるポーズを指定しても、参照元の画像のポーズが優先されます。
masterpiece, best quality, highly detailed beautiful face and eyes, 1 girl, black hair, black t shirt, skirt, from behind, sandy beach, sea
nsfw, flat color, flat shading, retro style, poor quality, bad face, bad fingers, bad anatomy, missing fingers, low res, cropped, signature, watermark, username, artist name, text
何か問題がある場合は、プロンプトや設定をよく確認してください。ただし、プロンプトの影響がどの程度及ぶのかについては不明です。髪色等は反映されるようです(反映されていないときも)。
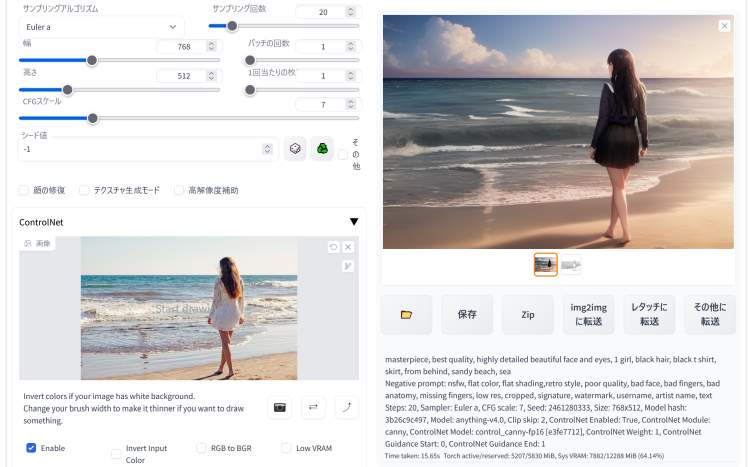
「ControlNet」の設定が正しく行われていると、上のように写真の女性のポーズと同じポーズの人物が描かれた画像が生成されます。
左の写真(ポーズの参照元)と右のAIイラスト(生成結果)を見比べてみてください。
 |
 |
| 最初の生成画像 | 次の生成画像 |
画像を連続で生成してもポーズはまったく同じです。二枚の写真を連続で開くと分かるのですが、同じ位置に同じポーズで立っています。その他の要素はそれなりに変わっています。
AI画像をプロンプトだけで出力しようとすると構図やポーズが毎回大きく変わってしまいます。けれども、「ControlNet」をうまく活用することでほぼ同じポーズを連続的に生成することが可能となります。
「ControlNet」を利用することで自分がイメージしているポーズの画像さえあれば、それをそのまま再現することができるのです。
つまり、これまでに生成した画像の中から「格好いいポーズ」や「可愛らしいポーズ」を厳選して、その画像を素材として次に生成する画像の登場人物に同じポーズをとらせることができるということです。
なお、「ControlNet」の利用を終えるときには「Enable(有効化)」のチェックを外すのを忘れないようにしてください。
(補足)「canny」(2023.4.13追記)
 |
 |
 |
| 元の画像 | 線画化(輪郭線の抽出) | 比較 |
「canny(キャニー法)」は元の画像から輪郭線を抽出して、次の画像の生成に適用する手法です。したがって、中央の線画を「ControlNet」の「ここに画像をドロップ-または-クリックしてアップロード」欄に配置しても画像を生成することができます。以下のプロンプトと併せてご利用ください。
その場合は前処理(=輪郭線の抽出)が不要となるため、「Preprocessor(プリプロセッサ)」に「none(なし)」を指定します。「モデル」には「control_canny-fp16」を指定します。
上の画像のプロンプトを参考までに掲載しておきます。サイズは512×768を2倍にアップスケールしています。
best quality, masterpiece, 1 girl, red hair, long hair, laugh, peace sign, black t shirt, blue pants, grass field
(worst quality, low quality:1.4), bad fingers
 |
 |
| 場所をroomに変更 | 場所をstreetに変更 |
場所を変更してみました。このようにポーズを完全に固定したまま場所だけを変更するといったことが可能です。髪色やtシャツの色を変えるといったこともできます。
高解像度化を行ったときには、手指の描写が通常よりも不安定になることからガチャは必須になります。上のような画像は10枚に1枚くらいの割合で生成されると思ってください。あとはポーズ等は完璧ですが手指の描写に問題があります。
抽出された輪郭線の中に「草」の描写があるため、右の画像のように道端に草が生えていることがあります。不要な部分はペイントソフトで削除してもよいかもしれません。

「棒人間」を使ってポーズを指定する(「openpose」の利用)
こちらはインターネット上で既に公開されている「棒人間」の画像を使って人物のポーズを指定する方法です。
この項目では、配付されている「棒人間」の画像や自分で生成した「棒人間」の画像を参照元の画像に指定して、新たに画像を生成する方法について言及しています。
他の方法と間違えないようにご注意ください。お手元に「棒人間」の画像があることが前提です。画像は誰かが公開してくれているものを探して使わせてもらってください。
使い方は先ほどとほとんど変わりません。
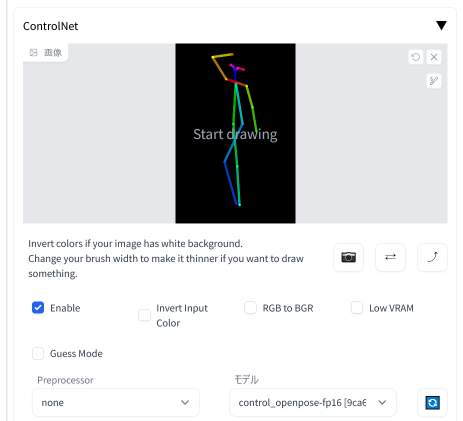
先ほどと同じく「Enable(有効化)」にチェックを入れます。
「Preprocessor(プリプロセッサ)」は「none(なし)」を指定します。繰り返しますが「棒人間」の画像が既に手元にある場合は「none(なし)」です。
「モデル」には「control_openpose-fp16」を指定します。
そして「棒人間」の画像を「ここに画像をドロップ-または-クリックしてアップロード」欄に配置してください。
あとはいつもと同じように適当なプロンプトとネガティブプロンプトを入力して、各種設定を済ませてから「生成」ボタンをクリックするだけです。
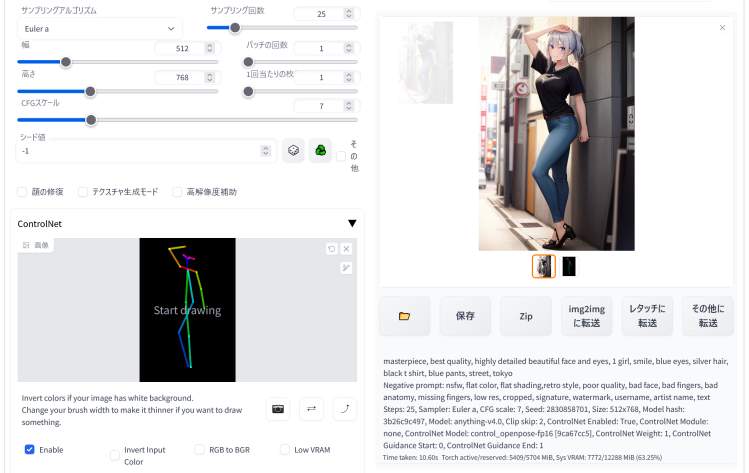
そうすると上のように「画像」と「某人間の画像」の二枚が出力されます。左の画像(=手を上げて足を組んだポーズ)と生成された画像を見比べてみてください。
参照元の画像と同じようなポーズの人物が描かれた画像が生成されていることがお分かりいただけると思います。これで望んだポーズをキャラクターにとってもらうことができるようになりました。
(追記)こちらも使用したプロンプトを掲載しておきます。
masterpiece, best quality, highly detailed beautiful face and eyes, 1 girl, smile, blue eyes, sliver hair, black t shirt, blue pants, street, tokyo
nsfw, flat color, flat shading, retro style, poor quality, bad face, bad fingers, bad anatomy, missing fingers, low res, cropped, signature, watermark, username, artist name, text
 |
 |
こちらはその後に生成した画像です。同じ設定で画像を何枚も出力してみました。服の指定は「black t shirt(黒いTシャツ)」ですが稀に白に変わります。また、何も指定していない靴の表現は毎回変わります。
下は「blue pants(青いズボン)」を指定しているため、そちらはほぼ変わっていません。背景は「street, tokyo(道・東京)」という指定から逸脱することはないものの場所が毎回変わりますね。プロンプトも色々と工夫しないといけません。
なお、以下の「Openpose Editor」を利用することで自分でポーズを作成することができます。
(補足)「openpose」(2023.4.13追記)
「canny」のところで紹介した画像を元に「openpose」用の「棒人間」を作成しました。それが以下の画像になります。
|
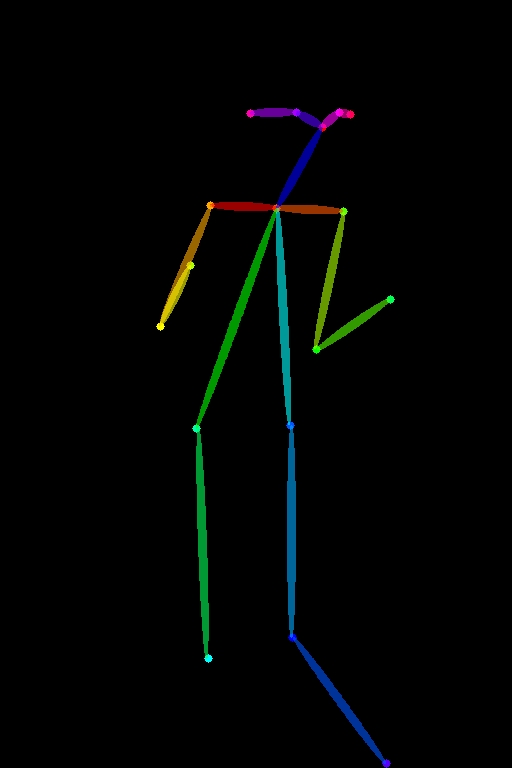 |
| 元の画像 | 棒人間化した画像 |
「openpose」で利用できるサンプル画像を用意しました。必要な方は自由に使ってください。上の「棒人間」画像を右クリックして「名前を付けて画像を保存」で任意の場所に保存するか、またはドラッグ&ドロップでデスクトップ等に配置してください。
それから「棒人間」の画像を「ここに画像をドロップ-または-クリックしてアップロード」欄に配置してください。この画像を使うことができるはずです。
プロンプトは先ほどと同じものですが、必要に応じて変更してください。以下の参考画像は太字の部分を一部変更したものになります。いずれも512×768を高解像度補助で2倍にアップスケールしています。
best quality, masterpiece, 1 girl, red hair, long hair, laugh, peace sign, black t shirt, blue pants, grass field
(worst quality, low quality:1.4), bad fingers
 |
 |
 |
| 場所をstreetに変更 | 髪色pink/場所paris | purple/white/paris |
プロンプトを変更することによってポーズを固定したまま細部を変更することができます。「棒人間」はポーズのみを指定しているので「表情」や「髪型」も変更可能です。
先ほどと同じように高解像度化を行ったときには、手指の描写が通常よりも不安定になることからガチャは必須です。上のような手指の画像は10枚に1枚くらいの割合で生成されます。
(棒人間ではなく)参照元の画像(たとえば、上で紹介している草原の画像)を配置して、プリプロセッサを「openpose_hand」、モデルを「control_openpose-fp16」にしても画像を生成することができるようですが、手指の認識精度はあまり向上していない気がします。単に使い方が分かっていないだけかもしれませんが……。「openpose_hand」はほぼ使っていないのでよく分かりません。


「ControlNet」は便利な機能だが利用には工夫も必要
「ControlNet」を上手く使えば、同じポーズのままで服装を変えたり、髪型や髪色を変えたり、背景を屋外から屋内に変えたりすることができます。
ただし、複雑なポーズは上手く生成されないことがあります。手指と脚の描写は通常の生成と同じように上手くいかないことが特に多い印象です。このあたりは使用している「(絵や写真の描写の方の)モデル」や「プロンプト」の内容などが生成される画像に影響している部分もあると思います。
その場合は、何度も生成を繰り返す、「モデル」を変更する、プロンプトに問題がないか確認する、棒人間の画像を変更する等、何か工夫をしないといけません。
「ControlNet」は大変便利な拡張機能ですが、うまく使いこなすためには試行錯誤が必要です。プロンプトや設定等の微調整も必要となります。
「ControlNet」では他にも、Blenderで作成した3Dモデルを使ったり、デッサン用の人形を使ったり、自分の写真を使ったりして登場人物のポーズを指定することができるようです。使い方をマスターすれば色々なところで応用が利きそうですね。
なお、大きな画像の生成方法は以下のページをご覧ください。低VRAMのグラフィックボードをお使いでも大きい画像を作成することは可能です。



